


At You Cannot Be Serious Stats we pride ourselves on taking a no-nonsense approach to tennis stats. What better way to walk the talk than by kicking the Substack off with a detailed explainer on our approach to player ratings?
Player ratings are a fundamental tool for measuring player skill over time and they will be an essential resource for the analysis on this Substack. The ratings we will use are going to be based on our custom-built ratings system, that you will only find on You Cannot Be Serious Stats. We have been developing and refining our system for years, and there is a lot we like about it. But every statistic has its limitations. Since we expect to make frequent use of these ratings, we wanted to give an overview of how our approach works, what we think it does well, and where it might fall short.
The Science of Player Ratings
The purpose of player ratings are to measure a player’s ability versus their competitors at any point in time. The Elo system has proven to be one of the most consistent and reliable performers at this task because of it’s dynamic self-correcting formula. A number of more modern systems, like Glicko, TrueSkill, and our own, build on this same principle. So let’s review the basics.
Standard Elo consists of a prediction and update rule. Prediction rule, predicts the chance that player i will defeat player j according to the pre-match difference in player ratings,
which is a logistic curve with scaling factor s. Player ratings aren’t known but the prediction rule supposes that, if we did know them, the gap in ratings would be a strong measure of match outcomes.
When the actual win result is known (W) each rating is updated with the rule,
with learning rate K, which sets the maximum rating change possible based on a single match result. The update rule is basically a built-in negative feedback loop that is Elo’s way of making up for the mistake it may have made with the pre-match odds. So even if we start off with a silly guess, it doesn’t take long for Elo to arrive at a more reasonable rating that is consistent with a player’s results.
Our System
You Cannot Be Serious Stats is an Elo-based rating system with a number of bells and whistles that make it more suitable for rating pro tennis players. But first, we have to explain that the system is actually an ensemble of two systems. Both have many similarities so we will only highlight the key differences below.
System 1 Key Features
System 1 is an implementation of the margin of victory (MOV) system described here. With respect to System 2, this approach differs in the following ways:
The MOV is based on the difference in total games won.
There is a separate learning rate for Grand Slams, which results in matches at the majors having 15% more weight.
Players are penalized for excess absences from competition that are not during the off season, which is a proxy injury correction. Note that no absence penalty is applied for 2020 matches owing to the COVID pandemic.
Retirements count against the rating of the retired player but is not included in the rating update of the opponent.
System 2 Key Features
System 2 is an implementation of the Bayesian extension to Elo ratings detailed in this paper.
Like System 1, System 2 also incorporates a margin of victory, but uses the difference in percentage of service points won instead of games won.
System 2 is derived from first principles using an approximation to Bayes’ rule. When fitted to results from a single surface, it ends up being very similar, but not exactly the same, as the Elo update.
System 2 is extended to handle multiple surfaces, updating ratings across all of them at once after each match based on how related they are.
Best of Both Systems
We use an ensemble of both systems to make the most use of their separate strengths when rating players. A simple way to judge the quality of the ensemble rating is to use them to predict match outcomes and compare that to actual results. Using our system, since 2020, we predicted 74% of men’s Grand Slam matches and 73% of women’s Grand Slam matches correctly. Match results outside of Grand Slams tend to be more random, that is, there are more upsets. We do see a drop in performance when considering all matches at the Challenger level and above but we believe our system’s accuracy is still quite good, as it predicts 67% of men’s matches and 69% of women’s matches correctly overall.
Why Not Betting Odds?
Betting odds are another source of predictions about tennis outcomes, including match results. A combination of market incentives and ‘wisdom of the crowd’ effects tend to make sports betting odds the single best performing public resource for event predictions in sport.
Given the reliable track record of tennis betting odds, it’s reasonable to ask why we don’t make use of them in the You Cannot Be Serious Stats rating system? There are two main reasons. First, the way any particular exchange or bookmaker arrives at a set of odds won’t be known to us. So when the odds are off (think the 2022 World Cup predictions) it makes it impossible to know why, which stymies fine-tuning and further development of the system. Interpretation and refinement of the system are equally important to us, so this is a major drawback.
The second issue is that converting betting odds into ongoing player ratings isn’t that straightforward and would require some additional choices and assumptions. So, while betting odds have some information about player skill, they are not an explicit rating system.
Ratings vs Rankings
Another topic very related to player ratings is rankings. Both the men’s and women’s tours have an official ranking system that assigns a rank order to all active pro players at the start of each week. Rankings have an important role for tournaments because they directly influence main entry status and draw seedings.
Players earn their ranking according to their ranking points. These are the points accumulated during a 52-week period. The points may feel link a rating but they are not the same thing. Ranking points don’t consider all the results in a player’s career but only a select number in a 1-year window. Also, and, most importantly, the points don’t consider the difficulty of the match but rather distribute a fixed number of points based on the round and tier of the event. Further, the tours effectively use the ranking system to punish players who don’t play a ‘full’ calendar. With more top players becoming more selective about their schedule – Federer famously stopped playing clay events in the last years of his pro career – that penalty creates an odd negative correlation between ranking points and player ability. For all of these reasons, rankings should be considered an imperfect indicator of player skill.
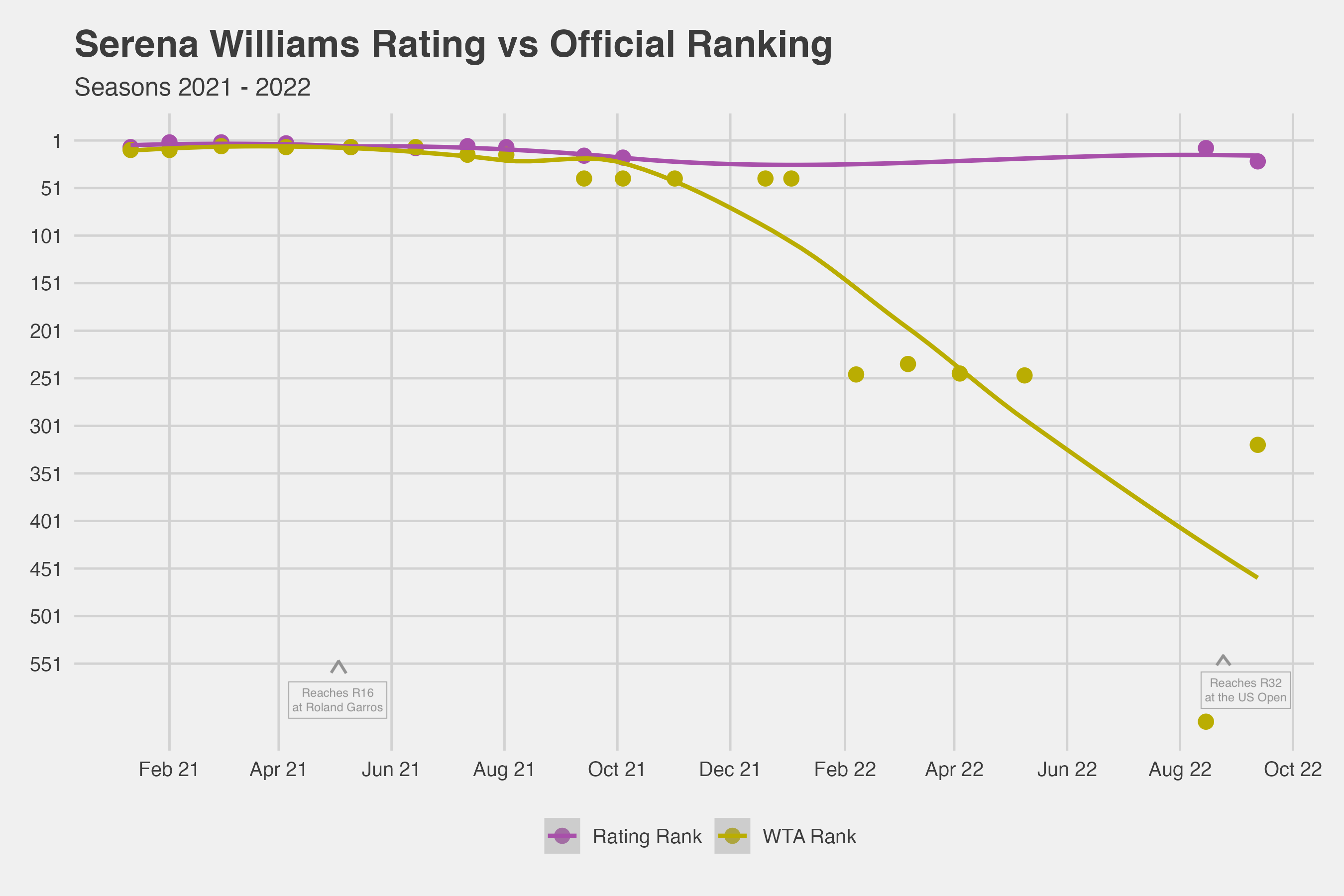
A few recent illustrations point out the flaws of player rankings and why ratings should be preferred when quantifying player ability. The final seasons of Serena Williams’s career were a classic example where player rankings overweighed regular play over actual skill (Figure 1). In 2021, Williams played very little outside of the Grand Slams and nothing for 12 months after a first round loss at Wimbledon. As a result, Williams entered her swansong hard court swing in the summer of 2022 with a ranking of 612! Williams’s player rating at that same time was still among the 50 highest of active players on tour, which was much more consistent with her performance at the 2022 US Open.
Figure 1. Serena Williams rank based on player ratings versus official WTA rankings for the 2021 and 2022 seasons.
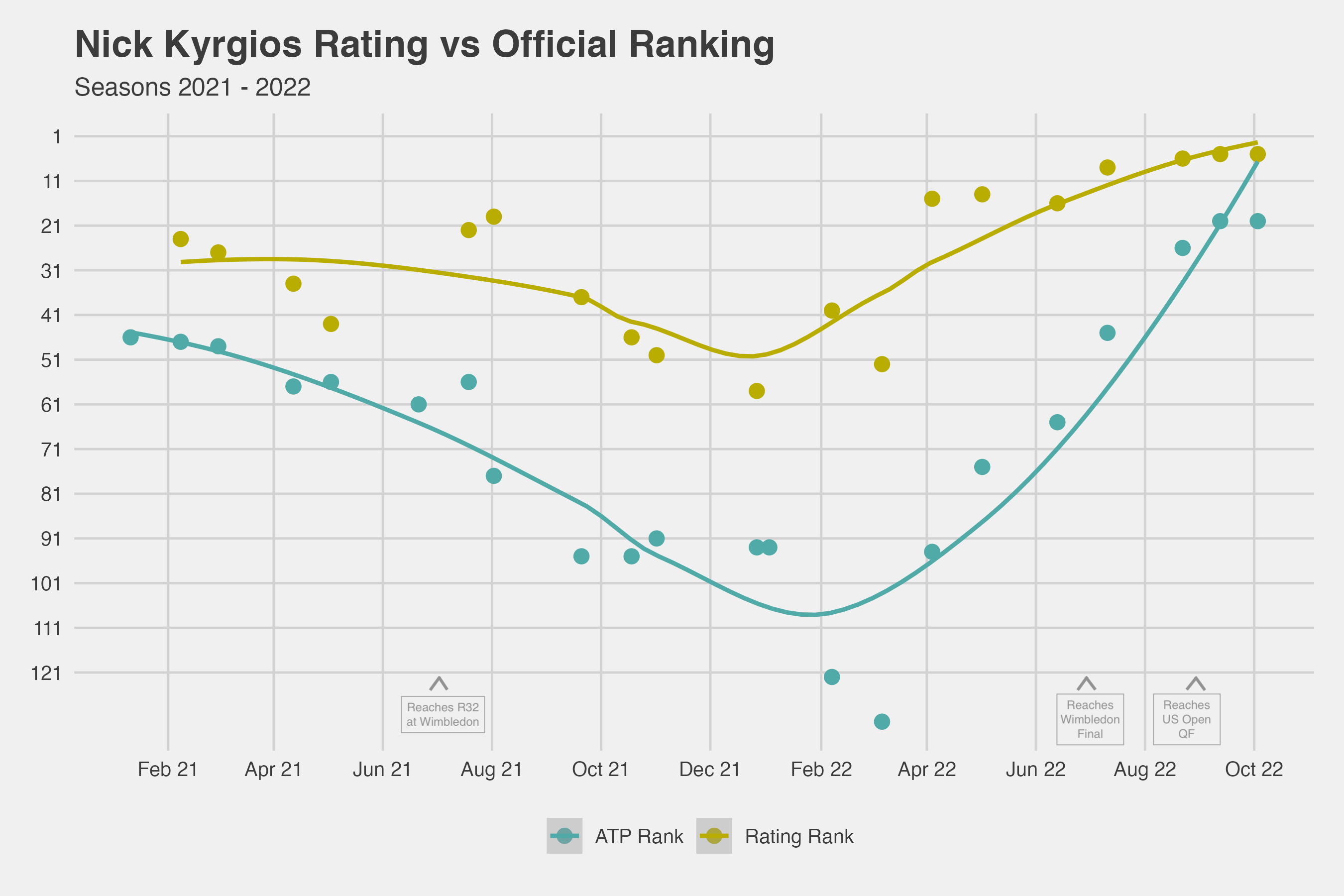
In some ways, it is a similar story for Nick Kyrgios. The fiery Aussie is known for taking his own path in all things and choices around his playing schedule are no exception. Kyrgios was especially choosy about playing events when Australia was still in a pandemic lockdown. His intermittent play in 2021 caused his ranking to plummet to outside 100 in August of 2021 (Figure 2). Yet Kyrgios’s player rating during this period was much more optimistic about his ability. While his ranking in the summer of 2022 would make his finalist result at Wimbledon seem like a shock, this result was no surprise from the perspective of his player rating, which put him well into the top 10 of men’s players at that time.
Figure 2. Nick Kyrgios rank based on player ratings versus official ATP rankings for the 2021 and 2022 seasons.
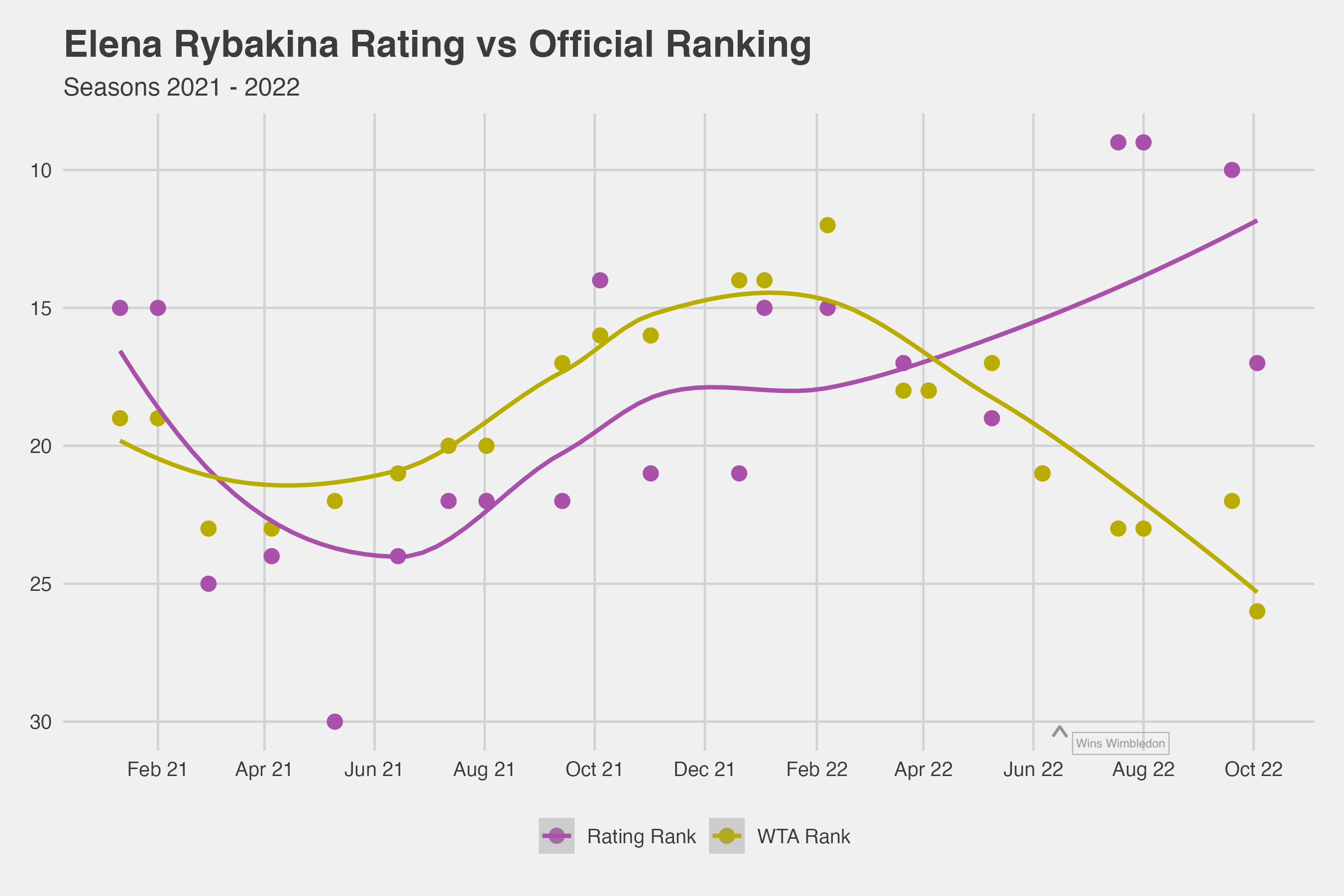
The 2022 also saw an unprecedented change to the ranking systems due to politics. This was the choice to take away Wimbledon ranking points as retaliation for Wimbledon’s ban on Russian competitors. As the women’s champion at Wimbledon in 2022, this decision by the tours had a major impact on the trajectory of her rankings in the last 6 months. Prior to that, Rybakina’s player rating and ranking points were fairly consistent. But that pattern was disrupted by the handling of a single Major event by the tours, when politics took priority over the integrity of the rankings system.
Figure 3. Elena Rybakina’s rank based on player ratings versus official WTA rankings for the 2021 and 2022 seasons.
As maintainers of the You Cannot Be Serious Stats rating system, we can assure you that the system’s validity and reliability are our top priority. Our system has been built on the principles of data science with the sole aim to accurately and consistently quantify player skill, and that will continue to guide how we maintain and refine the system over time.
This is awesome! You mentioned that betting odds weren't being incorporated in the ratings model, which makes sense to me, but I'm curious as to how much better they are at predicting outcomes - would you happen to have any benchmarks to compare against for the same time period?
Great article, will you publish your full rankings?